An introduction to Data Warehouse architecture
Learn about the recommended data warehouse architecture and what are the main layers of a typical data warehouse? Learn about the function of each layer and what the main modules are in each one. Furthermore, learn about new layers been added to the classical data warehouse architecture like data warehouse, data governance, data quality, meta-data management and so on.
Learning Objectives
Data warehouse is a term introduced for the first time by Bill Inmon. Data warehouse refers to central repository to gather information from different source system after preparing them to be analyzed by end business users through business intelligence solution. One of the main challenges that we faced before having data warehouses is to have isolated and un-connected data sources (known as data silos). Since that time, data warehouse evolved dramatically. Many layers been added to the original structure to enhance the overall architecture like data quality, staging area, data governance and meta-data management
By reading this article you will learn:
- Basic data warehouse model (mandatory layers)
- What are the main advanced data warehouse layers?
- What are the supporting data warehouse architecture layers
- Difference between classical data warehouse and active data warehouse
Summary/Description
Taha M. Mahmoud shows the basic data warehouse architecture and how to enhance it by adding different layers. He will describe the advantages and benefits that you will get by adding each layer.
The overall proposed solution architecture is displayed in the following figure:
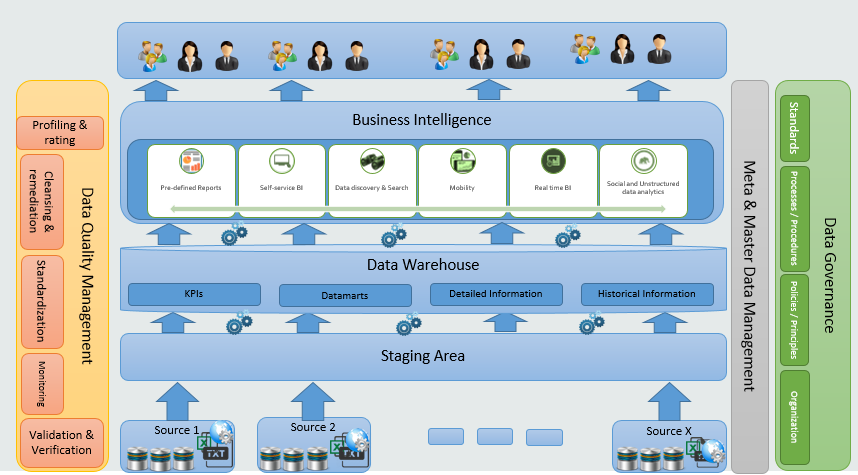 Data warehouse architecture contains the following main layers:
Data warehouse architecture contains the following main layers:
- Data Sources layer.
- Data Acquisition & Integration Layer.
- Enterprise Data Warehouse (EDW).
- Business Intelligence & delivery layer.
And the following supporting layers
- Data Quality.
- Data Governance.
- Master-data management.
Data warehouse main layers
Main data warehouse architecture layers are the main components of our suggested overall solution. Each layer will play a specific role and will act to produce the output for the next layer.
Data Sources layer
This layer will contains the defined data source which will be used to extract analytical information from, and load them into our data warehouse. The information can be existing inside the organization (internal source system) or out of it (external source system). Data can also exists in many and different formats like:
- Databases
- Web services
- Files (Excel, CSV, PDF, TXT,…etc.)
- We form
There are new data format started to appear in the horizon when Bid Data concepts were introduced. Social media or in our technical terms unstructured data is another source of information to consider now while designing your data warehouse architecture. Big Data can handle different types of information like recorded vice, scanned images and documents, un-structured text allowing us to analyses information that we have been able to analyze before.
Data Acquisition & Integration Layer – Staging Area
This part will be the intermediate layer between data sources and Enterprise data warehouse. The layer is responsible on data acquisition from different internal and external data sources. As data are stored in many different formats the data acquisition layer will use multiple tools and technologies to extract the required information. The extracted data will be loaded in a landing & staging area to pre-process the information by applying high level data quality checks. The final output of this layer is a clean data which will be loaded into Enterprise Data Warehouse (EDW). This layer contains the following components:
- Landing & staging area
- Data Integration Tool (ETL)
- Data Quality
Here we will describe each component:
Landing & Staging Area: The landing database will be used as a landing area that will store the data retrieved from information source system. The staging area will be used to pre-process information by applying data quality check before moving them to enterprise data warehouse data base. Data moved to landing and staging area source like (without any transformation). This layer is a database schema with addition to Big Data Eco system in case of we want to land un-structured data as well.
Data integration tool: Data integration tools which also known as Extract, Transform and Load tools (ETL) will extract information from source systems, do the required transformation and preparation for these data and finally load them in the target place. Informatica Power Center and IBM data stage are the most recognized ETL tools in the market.
Enterprise Data Warehouse (EDW)
A data warehouse is constructed by integrating data from multiple heterogeneous sources that support analytical reporting, structured and/or ad hoc queries, and decision making. This layer is the core and mandatory one for any data warehouse implementation. It is a database repository to store analytical and historical information which will be used by business intelligence solutions.
The two most commonly used approach for designing a data warehouse are introduced by Bill Inmon and Ralph Kimball. In general, both the approaches are defined as – Bill Inmon’s enterprise data warehouse approach (the top down design) – A normalized data model is designed first. Then the dimensional data marts, which contain data required for specific business processes or specific departments are created from the data warehouse.
Ralph Kimball’s dimensional design approach (the bottom-up design): The data marts facilitating reports and analysis are created first; these are then combined together to create a broad data warehouse.
In view of the business objectives – short term and long term data warehouse projects are targeted towards phased delivery approach for individual business areas in the organization.
The main features and benefits of EDW are:
- A Single, complete, and consistent store of data obtained from a variety of sources and made available to end users in many ways
- Create an infrastructure for reusing the data in numerous ways and to be the source of many systems
- complex architecture (business model rather than technical simple one) to maintain enterprise data for a very long time and to avail current and historical data for various users and systems
- Store aggregated and summarized data will enhance the retrieval time of the information and enhance overall performance.
- Store historical data to show trends and patterns.
- Give business users to display data gathered from different source systems in the same report or Dashboard.
- Secure the information by allowing only the right people to see their authorized information.
Business Intelligence layer.
BI tool will be the interface (front end) for the end business users. The BI layer will provide end users with the required information in many formats depending on their needs. Top Management and executives will need to see high level information to see highlights on the current situation from dashboards. Dashboards will contains KPIs, KQIs, KRIs and general metrics (analytics). Business and Data analysis on the other hand will need to access more information and the ability to drill up and down. This information usually provided by analytical reports through data discovery and modern BI tools. Finally normal users will need to access other raw information to do their daily job. This will be availed through normal traditional reports.
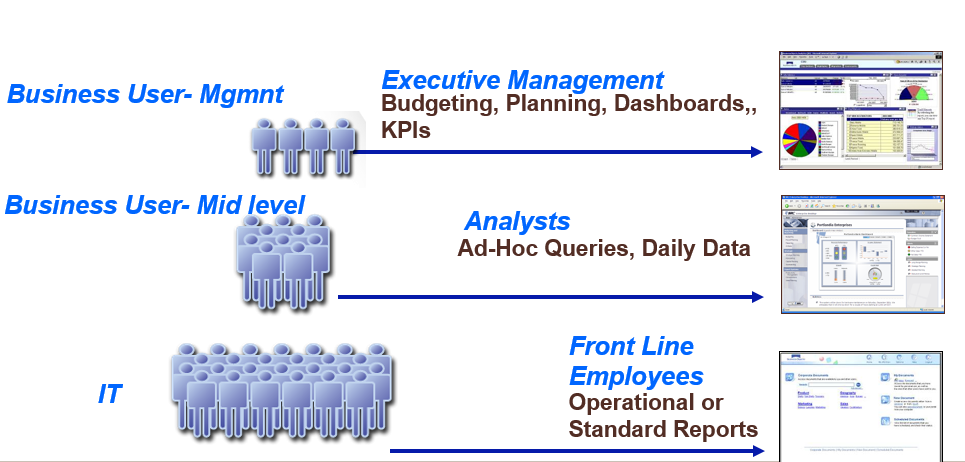 Data warehouse can be used when the organization BI maturity level enhanced based on end user adoption; to be the source for advanced analytical solutions as well. Advanced analytical solution will do more data processing to help the organization to achieve foresight through data mining, forecasting and identifying battens that may help the organization management and decision makers to be proactive. Achieving foresight will help the organization to act before the action and will help to enhance the overall performance.
Data warehouse can be used when the organization BI maturity level enhanced based on end user adoption; to be the source for advanced analytical solutions as well. Advanced analytical solution will do more data processing to help the organization to achieve foresight through data mining, forecasting and identifying battens that may help the organization management and decision makers to be proactive. Achieving foresight will help the organization to act before the action and will help to enhance the overall performance.
The next Era of BI is mobility and self-service. Mobility means that end user can access information using their cell phone, tablets and smart devices. The top management and executives can see information securely on the go at any time and no need to be located in the work place.
 The following items are the main BI components:
The following items are the main BI components:
- Presentation (semantic) layer.
- Static standard reports.
- Dashboards
- Data Discovery & exploration.
- Geo-Statistics.
- Security
Semantic layer
Semantic layer is a business representation of organization’s data that helps end users access data autonomously using common business terms. The aim is to insulate users from the technical details of the data store and allow them to create queries in terms that are familiar and meaningful.
Static Report
A static report is a report that is run immediately upon request and then stored, with the data, in the Data Warehouse. Using static reports, you view reports based on very large data sets, although static reports that are run on very large data sets can take a long time to complete. Static reports are pre-build reports to serve business users daily needs and usually we don’t expect a lot of modifications on those reports.
Dashboards
Dashboards often provide at-a-glance views of KPIs (key performance indicators) relevant to a particular objective or business process (e.g. sales, marketing, human resources, or production). The term dashboard originates from the automobile dashboard where drivers monitor the major functions at a glance via the instrument cluster. Dashboards give signs about a business letting the user know something is wrong or something is right. The corporate world has tried for years to come up with a solution that would tell them if their business needed maintenance or if the temperature of their business was running above normal.
Data discovery
Data discovery is learning something new as a result of an active interaction with data. The tools that help us perform data exploration that results in discovery are the real innovation behind data discovery. These data exploration tools focus more on the interaction between people and data, rather the production of static reports, imitation car dashboards and flashing stoplights.
Data exploration and discovery is not new. How many of us have used SQL queries or excel to look for answers to our questions? I’m not referring to SQL stored procedures or monthly excel reports; but rather, when we use these tools to resolve new questions we have never answered before. Sometimes this process of searching for the answer lasts days, but we now have a set of Data Discovery tools available that make data exploration and discovery easier.
Geo-statistics
Geo-statistics is a branch of statistics focusing on spatial or spatiotemporal datasets. Geo-statistics is applied in varied branches of geography, particularly those involving the spread of diseases (epidemiology), the practice of commerce and military planning (logistics), and the development of efficient spatial networks. Geostatistical algorithms are incorporated in many places, including geographic information systems (GIS) and the R statistical environment.
Security
The centralized architecture of many BI solutions means that lots of potentially sensitive data is aggregated in one place and used by many people. If an attacker gains access he can steal vast quantities of data or alter information used by many different business units.
The Security component provides a complete security system for your BI. Furthermore, the component provides ways to authorize authenticated users based on their roles.
The scope of our project to initially avail comprehensive semantic layer for the current available information. Then create some reports and dashboards to satisfy the organization BI needs. Ejada team will train the organization team to do their own reporting and how to enable self-service capabilities of the BI tool and how to create new customized reports based on the delivered semantic layer.
In Future; the organization can adopt a vision to raise the BI maturity level inside the organization by applying new modules and adopting new features. In the following section I will talk about data warehouse supporting layers.
Data warehouse supporting layers
Data warehouse supporting layers are standalone layers that can be exists even without data warehouse implementation they are organization wide layers and usually they interact with data warehouse main layers that I just explained.
Data Quality
Data quality is a critical part for any data warehouse implementation. Without clean and reliable data, no one will trust data warehouse and no one will have the confidence to take decisions based on the figures displayed in business intelligence solution reports. Actually data quality practice is a standalone and can be implemented even if you don’t have a data warehouse. We will have a detailed article to talk about data quality in more details but for now we will focus on the part related to data warehouse architecture and implementation.
As we can see in the solution architecture diagram; data quality practice will start in the information stakeholder / data owner side [data sources]. The external data providers should maintain the data quality of information they have by do proper data quality check and to do proper data cleansing for the information before submitting it to the organization. This process will be handled through data submission or data exchange application. A data quality check will take place in the organization side to do 2nd layer of data validation and decide if the submitted information can be accepted or it should be rejected and ask the data owner to cleans the information and resubmit it again.
The actual data quality process will start when the data been loaded to the acquisition layer. The data quality engine will run the data and business validation rules. Find and report bad records and do any automatic correction if applicable. Sometimes, we may apply the correction in the data source (root cause) which is the best data quality fix, sometimes we may just apply work arounds to minimize the effect of the data quality issue. We may even apply our quality correction and fixes on the data acquisition layer only, if the clean data is only required by business intelligence solution to make sure that discussions are made based on a correct data. Data quality practice doesn’t end with a correction, as a regular monitoring is required to make sure that the fix is permanent and no new data quality issues been raised.
Metadata management
The Metadata management layer will serve three elements: technical metadata, business metadata and operational metadata. “Technical metadata” describes the shape, size and format of data, content, services, and business rules, and “business metadata” describes the business context for those assets. The linkage of business metadata to technical metadata through a common metadata repository facilitates collaboration and better communication between business and technical users.
The metadata management layer will provide the organization with expanded capabilities to help visualize data integration processes of any shape or form, such as those in third-party applications, extract, transform and load (ETL) tools. The metadata management will enable advanced flexibility and scalability to maintain and integrate metadata across enterprise landscapes. Metadata management outlines the complete lineage of fields from applications, reports or data warehouses back to source systems, surfacing the processes and transformations that occurred along the way.
Data Governance
Data Governance provides the guidance to ensure that data is accurate and consistent to meet the business goals of the organization. This is achieved by defining a set of standards and establishing an organization responsible for overseeing the implementation of the standards within the organization. Data Governance ensures the right people are involved in setting data standards and defining usage and integration across projects, subject areas and lines of business. The following points are the primary functions of a Data Governance Framework:
- Increase accuracy, consistency and confidence in data for fact-based decision making.
- Ensure that duplication of data used for fact-based decision making is minimized.
- Ensure data security and privacy is upheld.
- Monitor and improve DQ across the enterprise.
- Ensure compliance with industry regulations.
- Ensure users have access to quality data so they can perform their functions.
