Docile Your Big Data Using Hadoop
The beginning of Apache Hadoop cropped up in 2003. Distributed applications that process extremely massive amount of data is developed and carried out by Hadoop. It stores data as well as runs applications on clusters of commodity hardware and gives huge storage for any sort of data, great power of processing plus the capacity to deal with virtually unlimited simultaneous tasks or jobs. Further, it was planned to step up from solo servers to thousands of machines where every single machine will offer local computation and space. And, instead of depending on hardware to give great level of accessibility, the Apache Hadoop software library is aimed to identify and deal with failures at the application layer.
At a broader level, the four chief constituents of Hadoop ecosystem are Hadoop Common, Hadoop YARN, Hadoop Distributed File System, and Hadoop MapReduce.
Many business organizations have comprehended the significance of big data and realized how interesting patterns can be obtained via analyzing data. Hence, they are gathering huge data, measured in terabytes and petabytes, in order to identify enthralling data patterns so that their sales and revenues etc., can boost up. And to process and analyze big data, the first word that comes to one’s mind is Apache Hadoop, an open-source framework.
Key Concepts
By reading this article, you will learn:
- What are the chief aspects of Apache Hadoop?
- How to docile your big data using Hadoop?
- What is YARN and what are its fundamental elements?
- How Hadoop Distributed File System (HDFS) works?
- The idea behind MapReduce.
Many business organizations have comprehended the significance of big data and realized how interesting patterns can be obtained via analyzing data. Hence, they are gathering huge data, measured in terabytes and petabytes, in order to identify enthralling data patterns so that their sales and revenues etc., can boost up. And to process and analyze big data, the first word that comes to one’s mind is Apache Hadoop, an open-source framework.
Introduction
Lots of advancements have been made in the area of data processing. Initially, people worked on flat files and afterwards they moved to relational databases. At present, we are familiar and working on NoSQL. Basically, our needs have increased with the increase in the amount of obtained data. And, conventional patterns have become insufficient to fulfill our current requirements. However, if the size of the data stored in a database is in gigabytes, it can be processed and analyzed via the conventional patterns. But what if the size of the data is in terabytes and petabytes? How this giant data can be processed and analyzed? This article will not only clarify these questions but also elucidate how to docile the big data using Hadoop.
Big data is being generated at a constant rate. It is getting from many sources at a startling rate, capacity and diversity. The way individuals work together in a company is being transformed by big data. Also, insights from big data can facilitate personnel to make decisions in a better way— increasing customer engagement, enhancing processes, avoiding risks and scam, and maximizing novel bases of revenue. Today, companies are pretty smart. They have comprehended the significance of data and realized how interesting patterns can be obtained via analyzing data. Hence, they are gathering huge data, measured in terabytes and petabytes, in order to identify enthralling data patterns so that their sales and revenues etc., can boost up. But ever-increasing demand for insights needs an essentially novel attitude to architecture along with tools and processes.
To process and analyze big data, the first word that comes to one’s mind is Hadoop, an open-source framework. The beginning of Apache Hadoop cropped up in 2003. Distributed applications that process extremely massive amount of data is developed and carried out by Hadoop. It stores data as well as runs applications on clusters of commodity hardware and gives huge storage for any sort of data, great power of processing plus the capacity to deal with virtually unlimited simultaneous tasks or jobs. Further, it was planned to step up from solo servers to thousands of machines where every single machine will offer local computation and space. And, instead of depending on hardware to give great level of accessibility, the Apache Hadoop software library is aimed to identify and deal with failures at the application layer. Thus, in this way it delivers an extremely accessible service coping with a cluster of systems, each of which may perhaps be inclined to failures.
The following section will talk about the Hadoop’s architecture and how this open source framework achieves its objectives. In addition to this, how to develop a MapReduce application will also be explained from an advanced perspective.
An Elucidation of Hadoop Architecture
At a broader level, the four chief constituents of Hadoop ecosystem are shown in figure 1.
 The entire Java libraries, operating system level abstraction, essential Java files and script which are required to execute Hadoop is provided by Hadoop Common. Nonetheless, for both job scheduling as well as cluster resource management, the framework which is used is Yet Another Resource Negotiator (YARN). It is indeed a remarkable enabler for dynamic resource exploitation on Hadoop framework as individuals can execute a number of Hadoop applications devoid of facing troubles regarding the escalating amount of work. Besides, the three fundamental elements of YARN are ResourceManager (one for each cluster), ApplicationMaster (one for each application), and NodeManagers (one for each node).
The entire Java libraries, operating system level abstraction, essential Java files and script which are required to execute Hadoop is provided by Hadoop Common. Nonetheless, for both job scheduling as well as cluster resource management, the framework which is used is Yet Another Resource Negotiator (YARN). It is indeed a remarkable enabler for dynamic resource exploitation on Hadoop framework as individuals can execute a number of Hadoop applications devoid of facing troubles regarding the escalating amount of work. Besides, the three fundamental elements of YARN are ResourceManager (one for each cluster), ApplicationMaster (one for each application), and NodeManagers (one for each node).
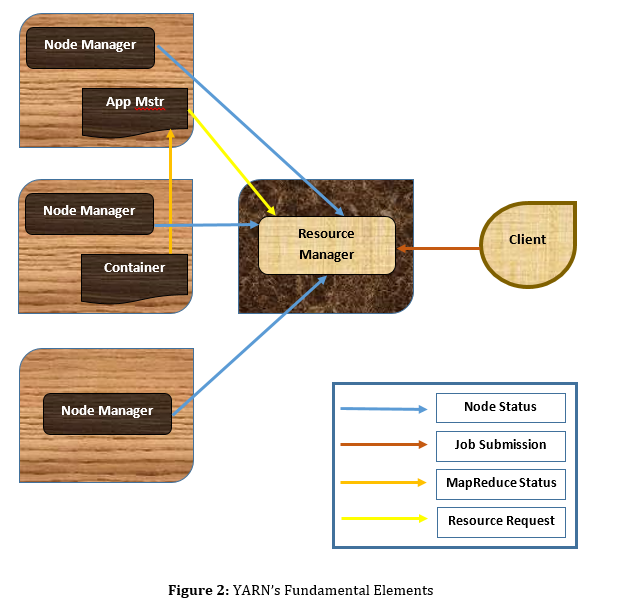 ResourceManager is accountable for acquiring inventory of accessible resources and carries out more than a few crucial services where Scheduler is considered as one of the most vital services. Resources are allocated to running applications by the Scheduler module. Further, status of the application is not examined or traced by the Scheduler.
ResourceManager is accountable for acquiring inventory of accessible resources and carries out more than a few crucial services where Scheduler is considered as one of the most vital services. Resources are allocated to running applications by the Scheduler module. Further, status of the application is not examined or traced by the Scheduler.
A devoted ApplicationMaster instance is possessed by every single application running on Hadoop. At regular intervals, a heartbeat message is transmitted to the ResourceManager by every single application. Moreover, if required, each application demands for further resources. From demanding extra containers from the ResourceManger, to proposing container release needs to the NodeManager, this complete execution of an application throughout its entire duration is watched over by the ApplicationMaster.
In addition to this, the NodeManager supervises containers all through their lifespans, observes usage of container resource, and links with the ResourceManager in a periodic manner.
Hadoop Distributed File System (HDFS)
To store an extremely huge data set in a consistent manner, and to spurt that data set at an elevated bandwidth to user applications, the Hadoop Distributed File System (HDFS) is designed. By means of distributing storage and reckoning across lots of servers, the resource can be raised with requirement whilst staying reasonable or cost-effective in all extent. Basically, HDFS was planned to operate on commodity hardware. In many aspects, this distributed file system goes in parallel with the current distributed file systems, however noteworthy differences exist. HDFS was intended to deploy on economical hardware and is considered as a great fault-tolerant. It not only offers great throughput access to application data but also appropriate for applications that encompass huge data sets.
Additionally some other significant aspects of Hadoop are as follows:
Partitioner: To distribute a specific investigation problem into practical lumps or pieces of data for utilization by a number of Mappers is the accountability of partitioner. If one is required to split up the data in his or her own way, one is unrestricted to make his or her own customized partitioner. In addition to this, in the HDFS, one of the partitioners is HashPartioner that splits up tasks by data’s rows.
Combiner: One will be required to create a combiner if due to certain reason, he or she wants to carry out a local reduce that will amalgamate data prior to transmitting it back to Hadoop. In essence, the reduce phase is carried out by the combiner. It classifies values accompanied by with their keys, however it does it on a particular node prior to giving back the key or value sets to Hadoop for appropriate shrinkage.
InputFormat: By and large, the default readers work well. However, if an individual’s data is not structured or not formatted in an acceptable manner then he or she will be required to make a norm InputFormat execution.
OutputFormat: In a certain InputFormat, Data will be read in MapReduce applications. After that, data will be written via an OutputFormat. Usual layouts can be supported with no trouble but if one wants to perform anything out of the ordinary, in that case he or she will be required to make his/her customized OutputFormat execution.
In addition, Hadoop applications are deployed in a set up that upholds its great degree of scalability and flexibility. These constituents consist of:
NameNode: It is considered as the master of the HDFS. Basically, it has a hold over DataNode which is considered as the slave of the HDFS. It not just comprehends where the entire data is put in storage but also understands the way the data is split into chunks, what nodes those chunks are organized to, plus the entire distributed filesystem’s vigor. All in all, in the complete Hadoop cluster, it is considered as one of the salient nodes. NameNode is possessed by every single cluster and in a Hadoop cluster, it is a specific point of flop.
Secondary NameNode: Basically, it observes the status of the HDFS cluster. Snaps of the data, resided in the NameNode, is taken by the Secondary NameNode. Instead of the NameNode, the Secondary NameNode can be utilized if the NameNode flunks. Nonetheless, involvement of an individual is required. Thus, from the NameNode to the Secondary NameNode, there will not be any automated failover. However, the Secondary NameNode will facilitate in order to make certain that loss of data is nominal. Secondary NameNode isalso possessed by every single cluster.
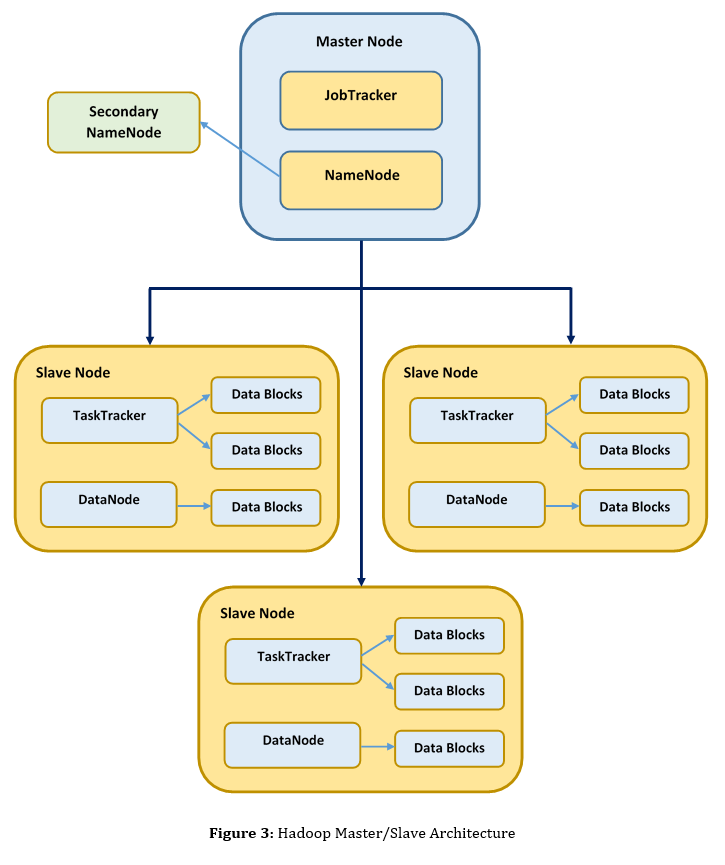 DataNode: In a Hadoop cluster, a DataNode will be hosted by every single slave node. It is accountable for carrying out data organization. DataNode inspects its data chunks from the HDFS and handles the data on every single physical node. Furthermore, the NameNode will be reported back alongside the status of data organization.
DataNode: In a Hadoop cluster, a DataNode will be hosted by every single slave node. It is accountable for carrying out data organization. DataNode inspects its data chunks from the HDFS and handles the data on every single physical node. Furthermore, the NameNode will be reported back alongside the status of data organization.
JobTracker: The link flanked by the application and Hadoop is the JobTracker. For each Hadoop cluster, a single JobTracker is aligned. It is accountable to develop an implementation plan when a code is given in to the Hadoop cluster for execution. Besides, the implementation plan comprises: finding out the nodes that encompass data to work on, organizing nodes to keep in contact with data, scrutinizing going on tasks, and starting the tasks again if they flop.
TaskTracker: A TaskTracker will be encompassed in every single slave node. Fundamentally, it is accountable for both carrying out the tasks which are delivered to it via the JobTracker as well as conveying the job’s status with the JobTracker.
The associations flanked by both master node as well as the slave nodes is depicted in Figure 3. NameNode and JobTracker are considered as the two chief components of the master node. Aforementioned, the in-charge of the entire data who also handles the cluster is the NameNode whereas the execution of the code when it is given in to the Hadoop cluster is handled by the JobTracker. In addition, DataNode and TaskTracker are encompassed in every single slave node. From the JobTracker, the TaskTracker gets its guidelines and not only carries out map but also cuts processes. Whereas, from the NameNode, the DataNode gets its data. And, the data comprised on the slave node is also handled by it. Last but not least, to keep informed from the NameNode, a Secondary NameNode is existed.
MapReduce
MapReduce is considered as the focal point of Hadoop. In a Hadoop cluster, MapReduce, a programming paradigm, takes into account great scalability thru hundreds or thousands of servers. The work flow of MapReduce goes through diverse stages and the HDFS will store the upshot with replications. Its all-inclusive jobs, carrying out on a number of nodes exist in the Hadoop cluster, will be looking after by the Job tracker. In order to schedule jobs, an imperative role is played by the Job tracker which not just trails the whole map but also reduces jobs. Besides, Task tracker carries out the task of map and reduce.
Fundamentally, two processing stages are involved in the architecture of MapReduce. Map stage is considered as the initial stage while the other is reduce stage. The initial stage gets a data set and transforms it into another data set, where particular components are split into tuples. On the other hand, second stage gets the output from a map as input and blends the data tuples into a reduced tuples’ set. In Task tracker, the actual process of MapReduce is occurred. Besides, intermediate process will be occurred in the middle of map and reduce stages. Certain processes, for instance shuffle and categorization of the mapper output data, will be carried out by the intermediate process.
As a final point, at Apache, other projects which are related to Hadoop comprise: AmbariTM, AvroTM, CassandraTM, ChukwaTM, HBaseTM, HiveTM, PigTM, SparkTM, TezTM, and ZooKeeperTM. They will be discussed in the upcoming article.
